Identifying galaxy groups and clusters in the high-z universe
Galaxies are not distributed at random. Rather, they are found to be clustered, with half or more of them residing in groups (with intermediate-to-low abundance of member galaxies) or clusters (with high abundance). Galaxy groups and clusters are commonly used to link galaxies with their host dark matter halos, as current galaxy formation models predict that galaxies form and evolve in dark matter halos. Therefore, identification of galaxy groups from observational samples is a crucial step toward a complete picture of the galaxy-halo connection. In the past decades, much effort has been dedicated to identifying galaxy groups in various galaxy surveys, both photometric and spectroscopic. Most of these studies have been limited to low-redshift surveys such as the Sloan Digital Sky Survey (SDSS). Next-generation redshift surveys will extend these to high redshifts, such as the Subaru Prime Focus Spectrograph (PFS) project which will observe about 0.3 million galaxies at 0.7 < z < 1.7 over ~15 square degrees in the sky -- an ambitious survey that is a factor of 10 larger than existing surveys at similar redshifts such as zcosmos.
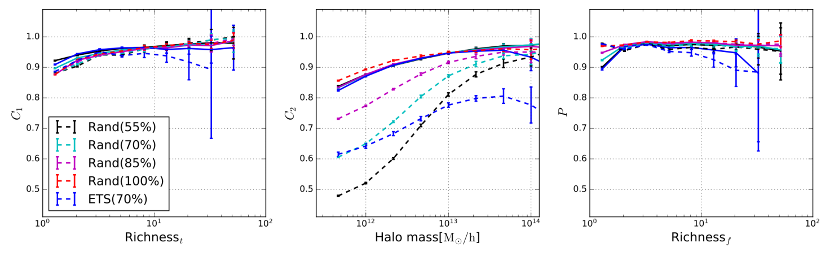
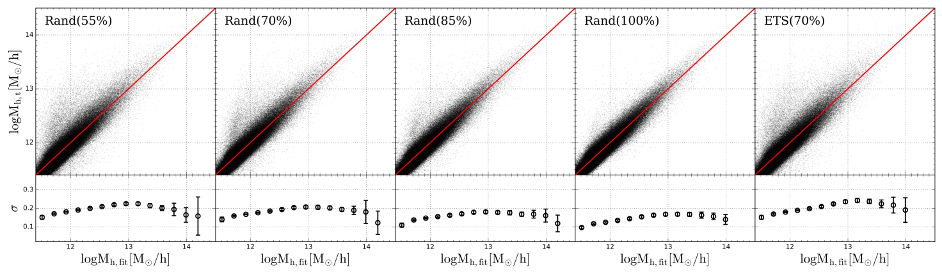
Surveys at high redshift suffer from incompleteness due to high observational expense, which makes it much more difficult to reliably identify galaxy groups. A research team led by Kai Wang, a PhD student from the Department of Astronomy (DoA) at Tsinghua University, including Prof. Houjun Mo from the University of Massachusetts, Prof. Cheng Li from DoA, and his PhD students Jiacheng Meng and Yangyao Chen, has developed a new group finder pipeline for identifying groups of galaxies from high-z incomplete spectroscopic data. To overcome the effect of the high incompleteness, photometric data in the same fields are used in addition to the spectroscopic sample, giving rise to group catalogs with both high completeness (>90%) and high purity (>80%) [see Figure 1], as demonstrated by the mock catalogs constructed by the same team (which will be presented in a parallel paper led by Jiacheng Meng). For each galaxy group, a dark matter halo mass is estimated using the technique of machine learning. Tests show that the standard deviation of the estimated halo masses around the true values is less than 0.25 dex for all masses [see Figure 2].
As an application, the group finder is applied to the zCOSMOS survey and a new group catalog is constructed and is public. In the near future, this group finder will be applied to next-generation redshift surveys such as the upcoming Subaru/PFS galaxy survey, in which the Tsinghua collaboration team is involved.
Relevant publication: Kai Wang, H. J. Mo, Cheng Li, Jiacheng Meng, Yangyao Chen, submitted to MNRAS. E-print available at https://arxiv.org/abs/2006.05426